USE greendb;
CREATE TABLE boargreendbd (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(60),
content LONGTEXT
);
DESC board;
현재 쿼리 실행 단축키 Ctrl + Shift + F9
CREATE INDEX index_title ON board (title);
SHOW INDEX FROM board;
BTREE가 뭘까?
비트리를 알기 전에 다음 개념을 알고 가자.
다음과 같이 데이터가 저장되어 있을 때
지수를 찾기 위해 검색을 하면 기본적으로 풀 스캔한다.

3번째 데이터에서 지수를 발견했을 때
스캔을 멈출까?
멈추지 않는다.
지수는 유일한 값이 아니기 때문이다.
아래에 지수가 또 있을지도 모르니 끝까지 스캔하는 것이다.
1. 검색은 full scan이 기본이다.
- 단점 : 값이 유일해야 풀 스캔하지 않는다.
찾으면 끝낼 수 있으니까
만약 다음과 같이 아래에 데이터가 더 있다고 할 때
지수를 찾기 위해 끝까지 풀 스캔한다.
총 7번을 검색하는데
이때 7번 검색하는 개념을 복잡도라고 한다.

무조건 풀스캔을 하는데 어떻게 하면 더 효율적으로 검색할 수 있을까?
정렬하여 저장한다.
재민이를 찾는다고 한다면
4번에서 재민이를 찾았지만
재민이는 유일하지 않기 때문에 아래 내려가서
재민이가 아닌 다른 값이 나온다면 검색을 끝낸다.

조회는 정렬이 가장 중요하다.
SELECT시에는 효과가 좋지만
INSERT시에 시간이 오래 걸린다는 단점이 있다.
2. 검색을 잘하려면 정렬을 해야 한다.
- 단점 : insert 시에 오래 걸린다.
무조건 정렬해야 하는 것은 아니다.
SELECT를 많이 하는 프로그램이면 정렬을 해야 하지만
INSERT를 많이 하는 프로그램이면 정렬하지 않고 데이터를 막 집어넣는 게 더 좋을 것이다.
어떤 요청의 효율을 극대화시킬지를 생각해봐야 한다.
이런 건 알고리즘이 결정하는 게 아니라 상황에 따라 판단해야 한다.
이 상황에는 UX가 많은 영향을 끼친다.
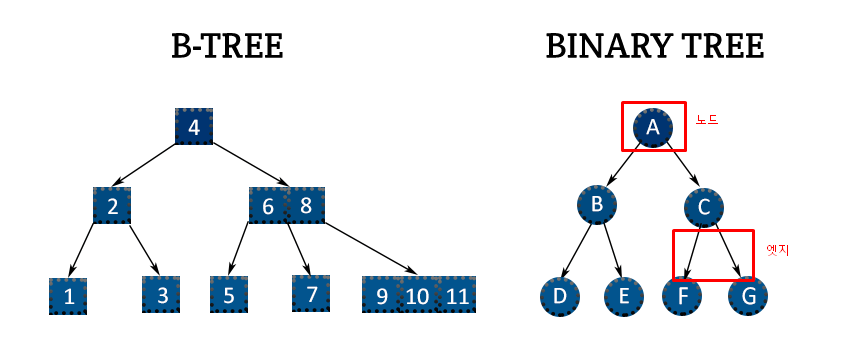
비트리와 이진트리는 다르다.
이진트리는 하이노드에 두 개 밖에 오지 못하지만
비트리는 여러 개 올 수 있다.
아래 노드들이 무조건 2개가 아니라는 것이다.
2개 이상 올 수 있는 것은 깊이가 얕아진다.
비트리의 왼쪽에는 작은 숫자, 오른쪽은 큰 숫자가 오게 된다.
정렬이 되어 있는 것이다.
5를 찾기 위해서는 4보다 크니까 오른쪽으로 가게 된다.
이때 왼쪽 노드 3개에 대한 시간 복잡도 3을 덜게 된다.
오른쪽으로 와서 6보다 작고 8보다 작으니까 왼쪽으로 가서 바로 5를 찾게 된다.
총 3번 만에 5를 찾게 되는 것이다.
풀스캔보다 훨씬 빠르지만 단점이 있다.
수정할 때 너무 복잡하다.
수정, 삭제가 빈번하게 일어나게 된다면
오히려 더 시간 복잡도가 늘어나게 된다.
정렬도 되어있고, 비트리 알고리즘으로 짜여있기 때문이다.
인덱스 검색이 바로 이 비트리 검색을 말한다.
인덱스를 만든다는 것은 데이터를 정렬해서 저장한다는 것이다.
검색할 때 매우 빠르다.
하지만 인덱스와 풀스캔을 비교해봐야 한다.
풀스캔이 더 좋을 수도 있다.
INSERT 할 때는 정렬하는 것보다 그냥 막 집어넣는 게 효율이 무조건 좋다!!
비트리는 실제 데이터를 말하는 것은 아니다.
목차를 말한다.
내가 만약에 홍길동을 찾고 싶으면 6번이라는 키 값에 저장되어 있는 것이다.
목차를 가지고 다이렉트로 데이터에 접근하는 것이다.
목차를 만들어놓으면 뭐가 좋을까?
목차를 찾을 땐 비트리로 찾고,
실제 데이터를 찾을 때는 풀스캔이 아닌 랜덤 액세스가 된다.
단순하게 비트리 시간 복잡도가 1이라고 가정해보자.
그리고 풀스캔과 비교해본다.
실제 하드디스크에서 약국을 찾는다고 할 때
① 목차에서 검색하고, ② K번지 찾아가고
③ 목차에서 검색하고, ④ O번지 찾아가고
⑤ 목차에서 검색하고, ⑥ M번지 찾아간다.
총 6번의 시간 복잡도가 걸렸다.
풀스캔을 하면 막 뒤져서 총 시간 복잡도가 8이 될 것이다.
만약 J번지에 저장된 데이터가 약국이었다면
풀스캔과 비트리의 시간 복잡도는 동일해진다.
목차 검색이 최고의 효율을 내는 1이라고 해도
풀스캔과 시간 복잡도가 같아졌다.

즉, 인덱스 검색은 내가 찾아야 하는 데이터가 적을 때 유리한 것이다.
보통 내가 찾아야 하는 데이터가 통상 15% 이하이면
인덱스를 거는 게 더 효율적이라고 말한다.

아까 만들었던 테이블에 내가 만든 인덱스 말고
PK에 인덱스가 걸려있다.
만든 적 없는 인덱스가 왜 걸려있을까?
PK는 유일하기 때문이다.
1번 데이터를 찾을 때 풀스캔으로 찾는 것보다
비트리로 찾는 게 더 효율이 좋기 때문이다.
내가 where절에 걸 때 인덱스를 탄다?
막상 걸었는데 효율이 좋지 않으면 리빌딩하면 된다.
고치면 된다는 말이다ㅎㅎ
버블정렬 알고리즘을 직접 짜 봤으면 알 테지만
1 2 3 4 5 6 순서를 거꾸로 바꾸기 위해서는
한 번의 순회로 끝나지 않는다.
하지만 정렬을 하지 않고 인덱스를 거꾸로 읽으면 끝나버린다.
인덱스를 거꾸로 읽으려면 hint를 걸어줘야 한다.
jpa를 사용하면 알아서 hint문을 걸어준다.
hint문 오라클 : /*+ INDEX_DESC (테이블 이름) */
데이터베이스가 무시하지 않고 읽는 주석으로 어노테이션과 같다.
board 테이블에는 아직 값이 없으니까
user 테이블로 확인해보자.
앗 mySQL 8.0부터 디센딩 인덱스를 지원해서 마리아 디비는 지원 안 하네요
마리아 디비 6.0 설치했었는데..
거꾸로 읽으려면 다른 방법 써야 해요
똑똑한 jpa 쓰면 이런 거 직접 안 써줘도 됨
SELECT *
FROM user
ORDER BY id DESC;
-- 위 쿼리와 같은 말 hint
SELECT *
FROM user
ORDER BY id * -1;
직접 코드를 작성해보자
실제 코드는 한 줄이면 된다.

properties는 컬럼명!
posts = postRepository.findAll(Sort.by(direction, properties));
posts = postRepository.findAll(Sort.by(Sort.Direction.DESC, "id"));
근데 실제 일어난 쿼리를 보니까 ORDER BY가 사용되었다.
정렬할 때 hint 안 쓰네
내 프로젝트가 대형 프로젝트이면 findAll 안 쓰겠다!
마리아 디비 버전이 낮아서 그런가?

[출처]
https://cafe.naver.com/metacoding
메타코딩 : 네이버 카페
코린이들의 궁금증
cafe.naver.com
메타 코딩 유튜브
https://www.youtube.com/c/%EB%A9%94%ED%83%80%EC%BD%94%EB%94%A9
메타코딩
문의사항 : getinthere@naver.com 인스타그램 : https://www.instagram.com/meta4pm 깃헙 : https://github.com/codingspecialist 유료강좌 : https://www.easyupclass.com
www.youtube.com



