자료형(type)은 데이터를 담을 박스를 효율적으로 만들기 위해 사용한다.
즉, 변수를 담을 상자의 크기를 지정하는 것이다.
자료형이 있는 언어를 정적인 언어라고 하고,
자료형이 없고 한 줄씩 해석(인터프리터)하는 언어를 동적인 언어라고 한다.
자바에는 8가지 기본 자료형이 있다.
이중에 우리는 4가지만 알고 가자.
| 데이터형 | 설명 | 크기(비트) | 최소값 | 최대값 |
| int | 부호있는 정수 | 32비트(4바이트) | 약 -21억 4천 | 약 21억 4천 |
| long | 부호있는 정수 | 64비트(8바이트) | 약 -900경 | 약 900경 |
| double | 실수 | 64비트(8바이트) | int와 숫자범위는 동일 + 소수점 |
int와 숫자범위는 동일 + 소수점 |
| boolean | true 또는 false | 1비트 | 해당 없음 | 해당 없음 |
정수를 표현할 때는 int(42억 9천, -21억~21억)를 사용한다.
우리가 프로그래밍하는 동안 int의 범위는 거의 벗어나지 않지만
은행과 같은 큰 숫자를 관리하는 회사에서는
21억의 범위를 넘을 것이다.
21억 이상을 표현할 때 long타입을 사용한다.
소수점이 있는 실수를 표현할 때는 double타입을 사용한다.
boolean은 논리형 타입으로 true 아니면 false만을 가질 수 있는 타입이다.
boolean의 크기는 1비트이다.
이 자료형으로 실습을 해보자.
package ex05;
public class VarEx02 {
public static void main(String[] args) {
int n1 = 10; // 4Byte
long n2 = 20; // 8Byte
double n3 = 30.1; // 8Byte
boolean n4 = true; // or false, 1Bit
System.out.println(n1); // n1 출력
System.out.println(n2); // n2 출력
System.out.println(n3); // n3 출력
System.out.println(n4); // n4 출력
}
}
main의 메모리에는 총 21바이트를 차지하고 있을 것이다.
실제 데이터가 저장되는 곳은 stack이고,
실행하기 위해 잠깐 담기는 곳이 queue이다.

int n1 = 10;
이라는 코드를 실행시키면 램의 1589번지에 값이 저장되었다고 하자.
우리가 메모리에서 n1을 찾기는 어려우니까
변수명과 주소 값이 적힌 중간 테이블을 이용해
컴퓨터에서 메모리의 주소 값인 1589번지를 찾아가서 10이라는 값을 가져온다.
내가 n1을 호출하면 컴퓨터는 최종 목적지인 메모리에 저장된 값을 찾아온다.
개발자는 n1 만 알고 있으면 된다.
n1만 알면 1589(주소)로 찾아가 준다.
n1은 1589(주소)가 아닌 10이다.
헷갈리지 않게 주의하자.
package ex05;
public class VarEx03 {
public static void main(String[] args) {
int n1 = 10; // 4Byte
long n2 = 20; // 8Byte
double n3 = 30.1; // 8Byte
boolean n4 = true; // or false, 1Bit
double t1 = n1;
}
}n1을 t1에 대입한다는 것은 주소를 대입할까, 값을 대입할까?
대입 연산이 일어날 때는 오른쪽에서 왼쪽으로 진행된다.
n1의 주소를 따라 가보니 끝에 10이라는 값이 있고 그 값이 t1에 대입되는 것이다.
그런데 정수 타입 n1을 실수 타입 t1에 대입했는데 오류가 나지 않는다.
왜일까?
메모리적으로 봤을 때 double의 공간이 int의 공간보다 더 크기 때문에
int를 double에 집어넣어도 오류가 나지 않는다.

double타입의 t1이 8Byte의 공간이 확보되었고
10이라는 값이 들어왔다.
하지만 n1의 값 10 또한 사라지지 않는다.
값이 복제된 것이다.
4Byte를 8Byte에 넣는 것은 메모리상으로 당연히 가능한데
이것을 묵시적 형 변환이라고 한다.
암묵적으로 타입의 변환이 일어난 것이다.
그렇다면 반대로
int t2 = n3;
double 타입의 n3을 int 타입의 t2에 대입할 수 있을까?
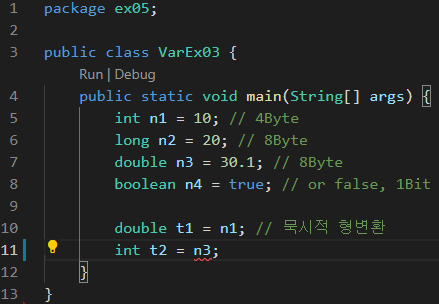
빨간 줄이 뜨면서 타입이 맞지 않다고 오류가 발생한다.
이때 형 변환이 가능하게 하기 위해서는
double 타입의 n3을 int에 맞게 몸을 깎아내야 한다.
이것을 명시적 형 변환이라고 한다.
명시적 형 변환은 바꿀 타입을 괄호 안에 써주면 된다.
그리고 결과값을 확인해보자.
package ex05;
public class VarEx03 {
public static void main(String[] args) {
int n1 = 10; // 4Byte
long n2 = 20; // 8Byte
double n3 = 30.1; // 8Byte
boolean n4 = true; // or false, 1Bit
double t1 = n1; // 묵시적 형변환
int t2 = (int)n3; // 명시적 형변환
System.out.println(t1);
System.out.println(t2);
}
}
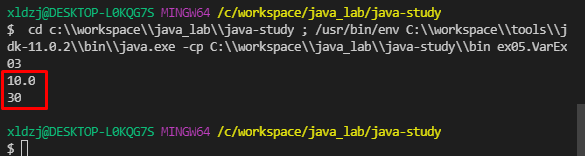
int타입인 n1이 실수형으로 바뀌고
double타입인 n3이 정수형으로 바뀐것을 확인할 수 있다.
package ex05;
public class VarEx03 {
public static void main(String[] args) {
int n1 = 10; // 4Byte
long n2 = 20; // 8Byte
double n3 = 30.1; // 8Byte
boolean n4 = true; // or false, 1Bit
long t3 = n1; // 묵시적 형변환
int t4 = (int) n2; // 명시적 형변환
int t5 = n4; // 오류발생 !
// 얘는 왜 안될까? boolean이 더 작은뎅
// 원리는 맞음 이건 그냥 자바문법에서 막아놓은것
}
}같은 정수끼리도 형 변환이 가능할까?
가능하긴 하지만 사용하지는 말자.
int를 long타입에 넣는 것 가능하다.
long을 int타입에 넣는 것은 불가능하기 때문에 명시적 형 변환을 해준다.
int t4 = (int) n2;
그러면 boolean타입은 int에 넣는 게 가능할까?
int가 4바이트고 boolean이 1비트라서
boolean이 int에 대입하는 원리는 가능하지만, 자바에서는 오류가 난다.
이건 그냥 자바 문법에서 막아 놓은 것이다.
소스코드를 살펴보면 대문자는 3가지에 사용된다.
파일 이름, System, String
클래스 이름에는 단어의 첫 문자를 대문자로 입력해준다.
내가 만들지 않은 클래스들을 라이브러리라고 하고,
System은 컴퓨터 모니터에 접근할 수 있도록 도와주는 도구이다.
문자열은 String 타입에 값을 받아주는데
String타입의 자료형 크기는 어떻게 될까?
package ex05;
public class VarEx04 {
public static void main(String[] args) {
// 1. 4가지 자료형 int, long, double, boolean
// 2. 문자열 : 자료형 알 수 없음
String s1 = "안녕하세요";
System.out.println(s1);
}
}문자 한 글자는 char타입이고 2바이트를 차지한다.
그렇다면 "안녕하세요" 문자열은 10바이트일 것이다.
10바이트를 기준으로 메모리를 확보했다가
나중에 이 문자열 s1이 5글자 이상으로 수정된다면
오류가 발생할 것이다.
이를 방지하기 위해 포인터를 이용해준다.
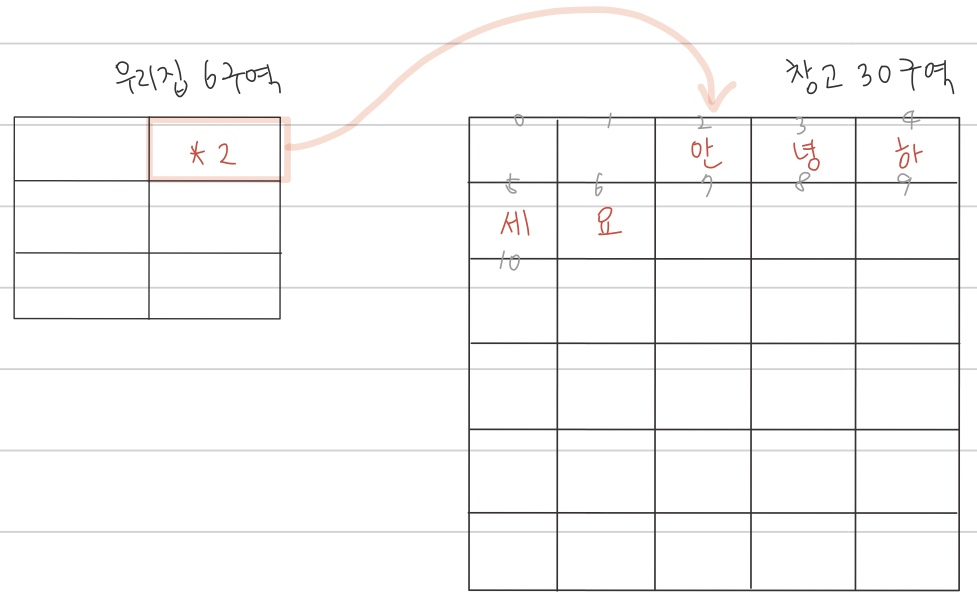
우리 집에 쌀 하나 들어갈 수 있는 박스가 6개 있다.
박스 크기에 딱 맞는 크기의 쌀 1개만 들어오는지 알고 있으면
박스 1개만 있어도 된다.
몇 개의 쌀이 들어오는지 모르는 상태라면 어떻게 할까?
창고 크기보다 더 큰 양의 쌀이 들어올 수 있으니 창고에 넣어두고
창고의 열쇠를 박스에 넣어둘 것이다.
이때 우리 집 박스가 stack이고
창고가 heap 공간이다.
창고의 열쇠가 heap의 주소를 참조하는 포인터이다.
내가 데이터의 사이즈를 확보하지 못하면 컴파일을 할 수 없기 때문에
사이즈를 모를 때 포인터를 사용한다.
이 주소는 4Byte 크기의 int로 저장한다.
우리 집에 박스가 6칸 있고 창고가 1000칸이라고 한다면
박스 1칸에 창고의 주소를 나타낼 수 있는 최소한 숫자 1000까지는
저장할 수 있어야 창고의 주소를 참조할 수 있다.
만약 String의 타입이 Byte였다면
저장할 수 있는 창고 공간이 255개 밖에 없기 때문에
int타입을 사용하여 49억 개의 창고를 사용할 수 있다.
만약 나중에 프로그래밍 언어가 발전한다면 이 크기가 달라질 수 있을 것이다.
그렇기 때문에 어떤 값이 들어올지 모르고
사이즈를 모른다면 무조건 주소를 참조할 수 있는 4Byte의 공간을 확보해두고
이 4Byte에는 주소가 저장된다.
위에 VarEx04.java 파일을 예시로 확인해보자.
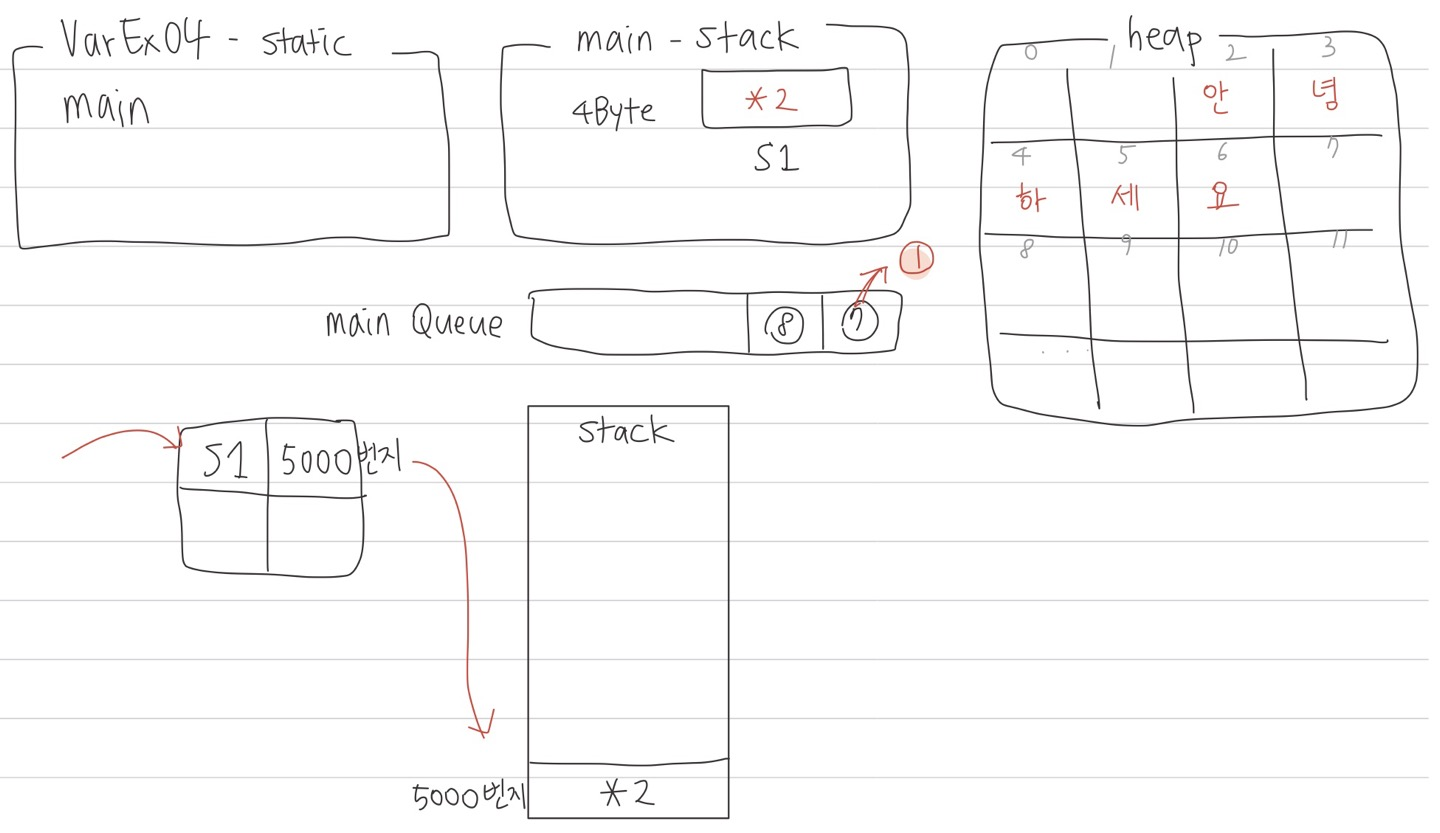
JVM이 static을 찾고 main을 찾아서
main의 stack이 열리면 main Queue가 생성이 되고
Queue에 문장이 쌓이게 된다.
그리고 ⑦번 문장(String s1 = "안녕하세요";)이 실행되는 시점에
어, String 타입이네?
들어오는 데이터의 양을 모르네?
그럼 일단 4Byte 공간 확보해둬야겠다!
하고 stack에는 이름이 s1인 4Byte 크기의 공간이 확보된다.
그리고 들어온 데이터는 heap에 동적으로 할당되고,
heap의 주소가 2번지라고 한다면 stack에는 *2 주소 데이터가 저장된다.
⑦번 문장의 일이 끝났으니 Queue에서 빠져나간다.
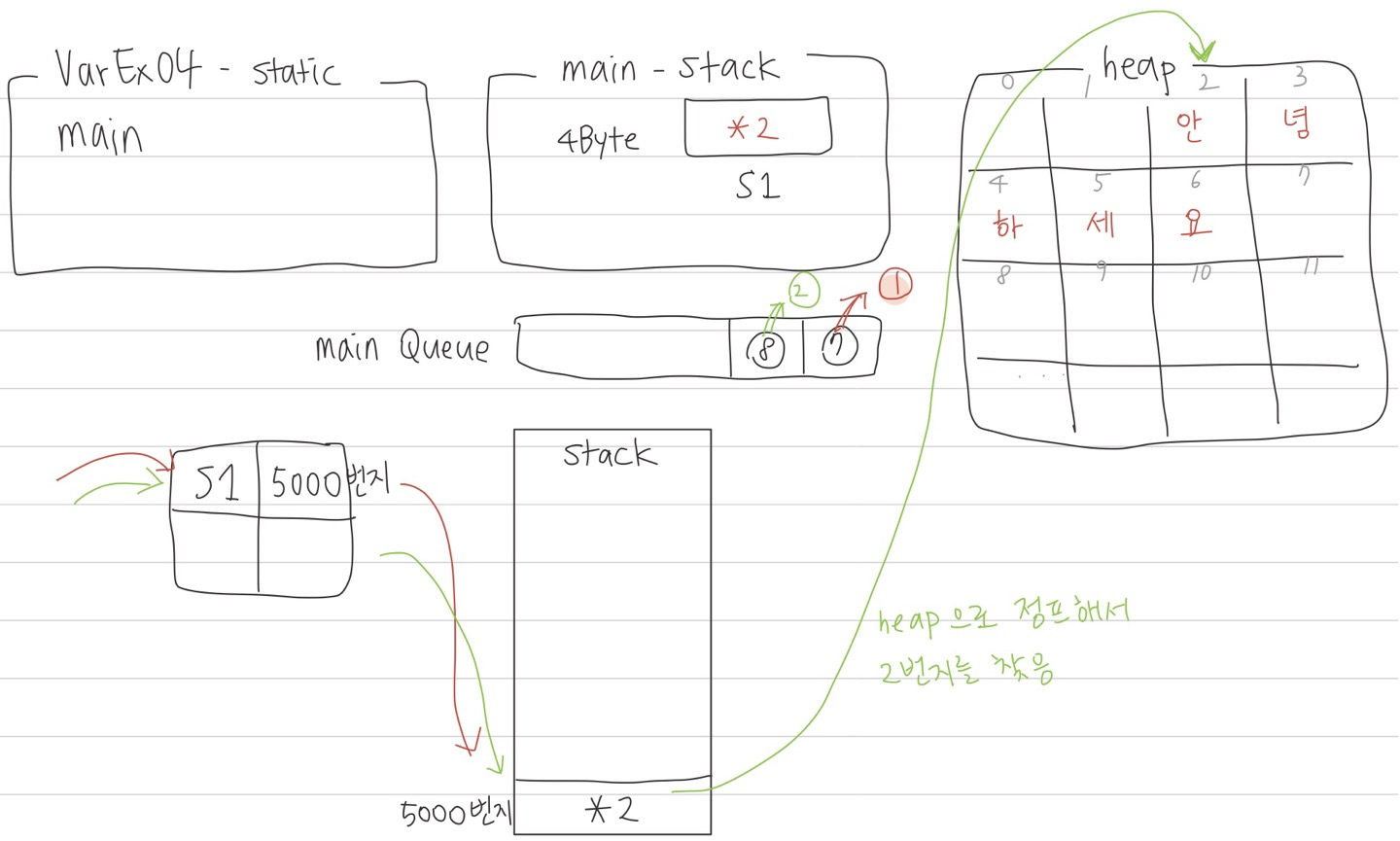
⑧번 문장(System.out.println(s1);)이 실행되는 시점에는
첫째, s1을 찾는다.
s1의 주소가 5000번지인 테이블을 확인하고
램에서 5000번지를 찾아 들어있는 데이터인 주소 *2를 찾는다.
둘째, 문장을 실행했을 때 메모리에 주소 값이 있으면 heap으로 점프해서 주소를 찾으러 간다.
실행시켜서 출력을 할 때 주소를 출력할 수 없으니 heap으로 점프해서 값을 찾은 다음 출력하는 것이다.
자바언어는 주소 참조를 찾아가면 무조건 값을 뱉어낸다.
이렇게 변수를 호출했을 때 메모리에서 주소를 돌려주는 것을
call by reference라고 한다.
기본 자료형은 크기를 모두 알고 있어서
정확한 크기의 메모리 할당이 가능하기 때문에
heap 영역을 사용할 이유가 없고,
stack에 주소 값이 아닌 실제 값이 들어있다.
이러면 변수를 호출했을 때 메모리에서 값을 돌려주는데
이것을 call by value라고 한다.
자바에서 기본 자료형이 아닌 모든 것이 call by reference이다.
package ex05;
public class VarEx04 {
public static void main(String[] args) {
// 1. 4가지 자료형 int, long, double, boolean
// 2. 문자열 : 자료형 알 수 없음
String s1 = "안녕하세요";
System.out.println(s1);
String s2 = s1; // 주소가 저장된다.
s2 = "반가워요"; // 새로운 heap 공간이 할당된다.
}
}
그렇다면 String s2 = s1;
이 문장의 결과에서 s2에는 s1의 값이 들어오게 될까, 주소가 들어오게 될까?
결론은 주소가 들어오게 된다.
결국 s1의 메모리에는 주소 값이 들어있기 때문에
메모리값을 대입하게 된다.
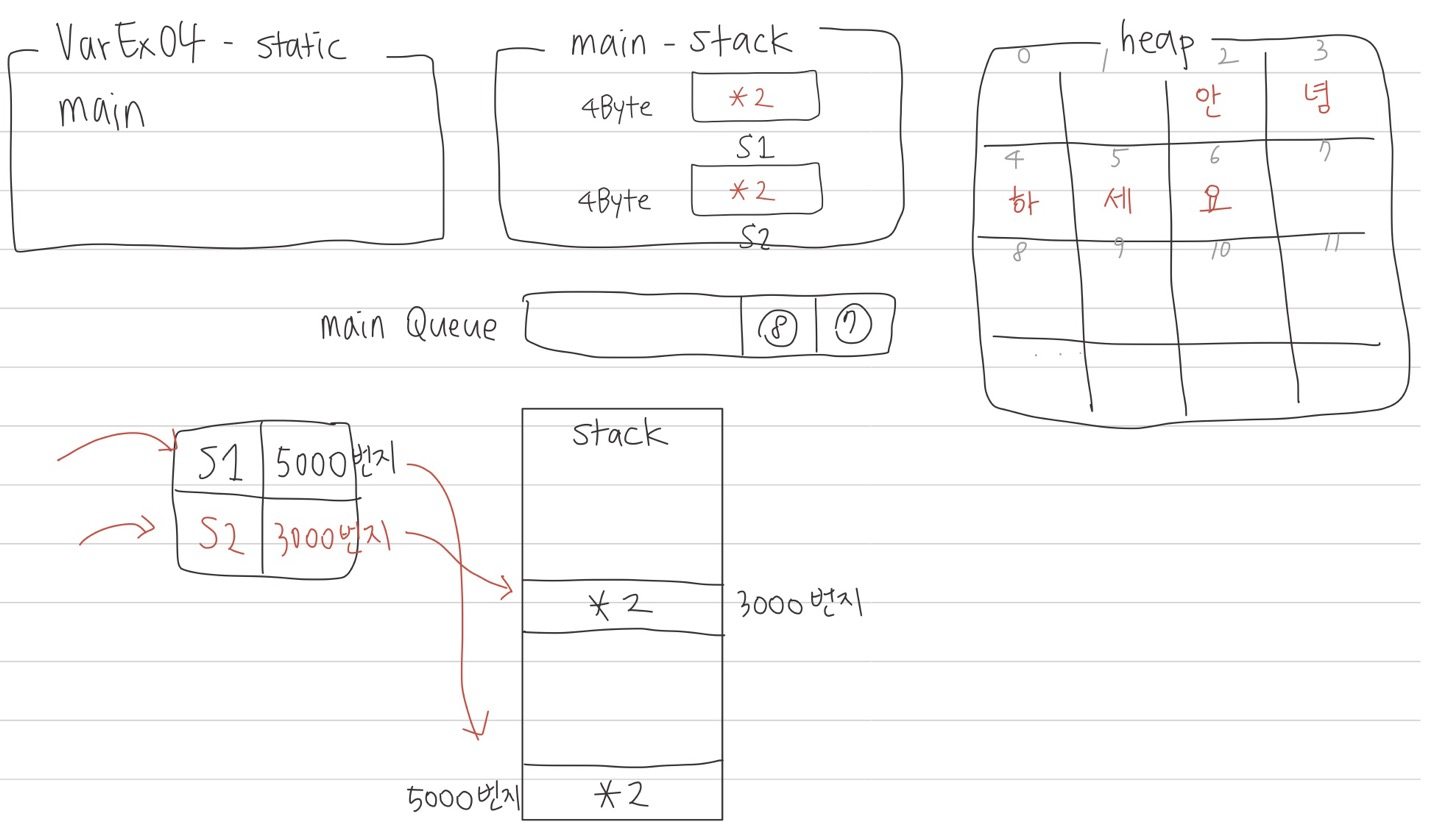
s2 이름을 가진 4Byte 크기 공간이 확보되고 주소 값 *2가 저장된다.
s2의 메모리 주소가 3000번지라고 하고
주소를 따라 3000번지를 가도 s1의 heap의 주소 값이 저장되어있다.
이때 메모리의 상태는 4Byte 크기의 s1, s2 2개 8Byte를 차지하게 되지만
heap은 메모리의 변함이 없다.
그러면 s2의 값을 바꿔준다면 s1의 값도 같이 바뀌게 될까?
(s1 = "반가워요";)
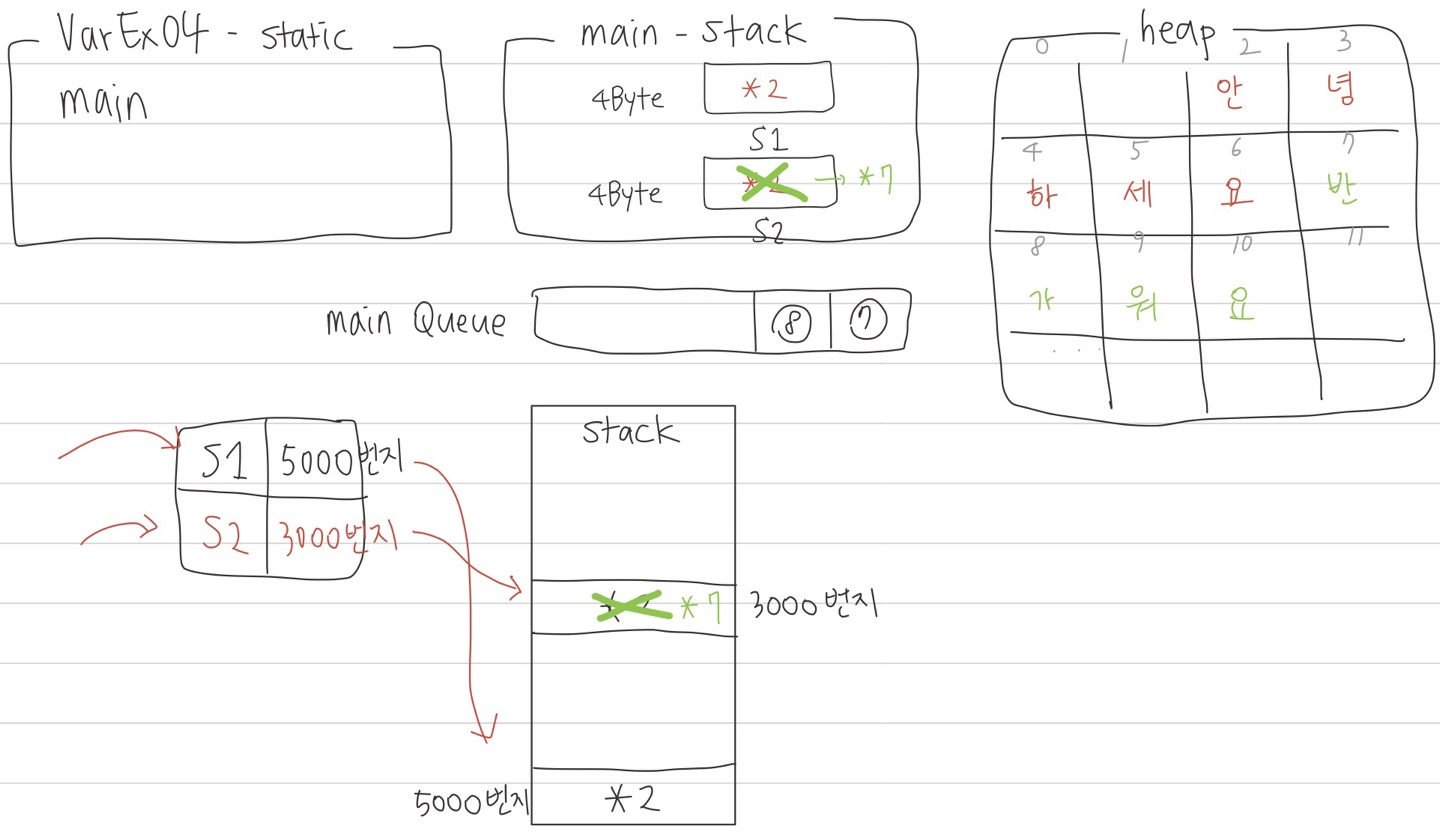
s1의 값이 바뀌는 게 아니라
heap에 새로운 공간이 할당되고,
s2의 메모리에 저장되는 주소 값이 *2가 아닌 *7로 바뀌게 된다.
내용을 정리해보자.
데이터의 크기를 알고 있다?
-> 4가지(int, long, double, boolean) 자료형 중 한 가지를 사용하고
이 변수에는 값이 직접 들어간다.
데이터의 크기를 모른다? (대표적으로 String)
-> 주소만 저장할 수 있는 4Byte 확보한다.
변수를 호출했을 때 주소 값이 나온다?
-> JVM이 점프해서 heap으로 간 후 주소를 찾아 값을 가져온다.
call by reference
변수를 호출했을 때 값이 나온다?
-> 기본자료형이고 크기를 알고 있는 데이터이다.
call by value
* 인터프리터 언어들은 한 줄씩 읽고 데이터의 크기를 다 모르기 때문에
모두 call by reference임
[출처]
https://cafe.naver.com/metacoding
메타코딩 : 네이버 카페
코린이들의 궁금증
cafe.naver.com
메타 코딩 유튜브
https://www.youtube.com/c/%EB%A9%94%ED%83%80%EC%BD%94%EB%94%A9
메타코딩
문의사항 : getinthere@naver.com 인스타그램 : https://www.instagram.com/meta4pm 깃헙 : https://github.com/codingspecialist 유료강좌 : https://www.easyupclass.com
www.youtube.com



