post 테이블
id, title, content
user 테이블
id, username, password
테이블 간의 연관 관계가 필요하다.
글 하나는 한 명의 유저가 쓴다.
1:1의 관계이다.
유저 한명은 여러 개의 글을 쓸 수 있다.
1:N의 관계이다.
관계는 큰쪽으로 따진다.
1:N의 관계에서 N이 FK(외래키)를 가지고
N이 드라이빙 테이블이 된다.
한번 이해했으면 이제 외워서 사용하자!
ORM(Object Relational Mapping) : 객체와 관계형 데이터베이스의 데이터를
자동으로 매핑(연결)해주는 것
자바는 객체지향 언어인데
DB와 연결을 위해 모델을 만들 때
오브젝트 타입 속성을 만들 수 없다.
디비에 오브젝트를 넣을 수 없으니까!
ORM에 대해선 다음에 더 자세히 배우자.
초기에는 타입 불일치 모순 그대로 사용하였다.
class User {
int id;
String username;
String password;
}
class Post {
int id;
String title;
String content;
int userId;
}userId는 외래키로서 User의 정보를 담고 있어야 하는데
DB는 오브젝트 타입을 사용할 수 없기 때문에
userId를 int 타입으로 받아왔었다.
그리고 새로운 클래스를 하나 더 만든다.
모델링을 위한 클래스가 아닌
user 정보를 담기위해 필요한 클래스를 만드는 것이다.
class PostAndUser {
int id;
String title;
String content;
int userId;
String username;
}
그리고 직접 조인하여 필요한 값을 뽑아내
PostAndUser 클래스로 옮겨준다.
SELECT p.id, p.title, p.content, u.id, u.username
FROM post p inner join user u
ON p.userId = u.id;
클래스만 더 늘어나고 귀찮으니까
이후에 다른 방식이 나왔다.
class Post {
int id;
String title;
String content;
User user;
}SELECT *
FROM post p inner join user u
ON p.userId = u.id;두 테이블을 직접 JOIN한 후
모든 값을 다 들고와서(*)
매칭 시켜 쏙쏙 넣어주는 것이다.
이 과정을 직접 만들었다.
이제 ORM 기법을 사용해보자.
class User {
int id;
String username;
String password;
}
class Post {
int id;
String title;
String content;
int userId;
}타입이 불일치한 모순을 해결하기 위해
중간에 미들웨어를 하나 둔다.
이 미들웨어에서 일어나는 과정을 살펴보자.
우선 DB의 post 테이블에서 id가 1인 게시글을 SELECT 해준다.
SELECT * FROM post WHERE id = 1;ResultSet에는 (id, title, content, userId) = (1, 제목1, 내용1, 1) 값이 들어간다.
이 데이터를 자바의 Post 오브젝트에 차곡차곡 넣어주는데
FK인 userId만 빼고 넣어준다.
Post p = new Post(1, "제목1", "내용1", ?);
그리고 ResultSet에 담긴 userId로
User 테이블에서 다시 한번 SELECT 한다.
SELECT * FROM user WHERE id = 1;ResultSet에는 (id, username, password) = (1, ssar, 1234) 값이 들어간다.
이 데이터를 자바의 User 오브젝트에 차곡차곡 넣어준다.
User u = new User(1, "ssar", "1234");받아온 이 User 오브젝트를
비워뒀던 Post 오브젝트 마지막 user 자리에 넣어주면 되는 것이다.
p.setUser(u);
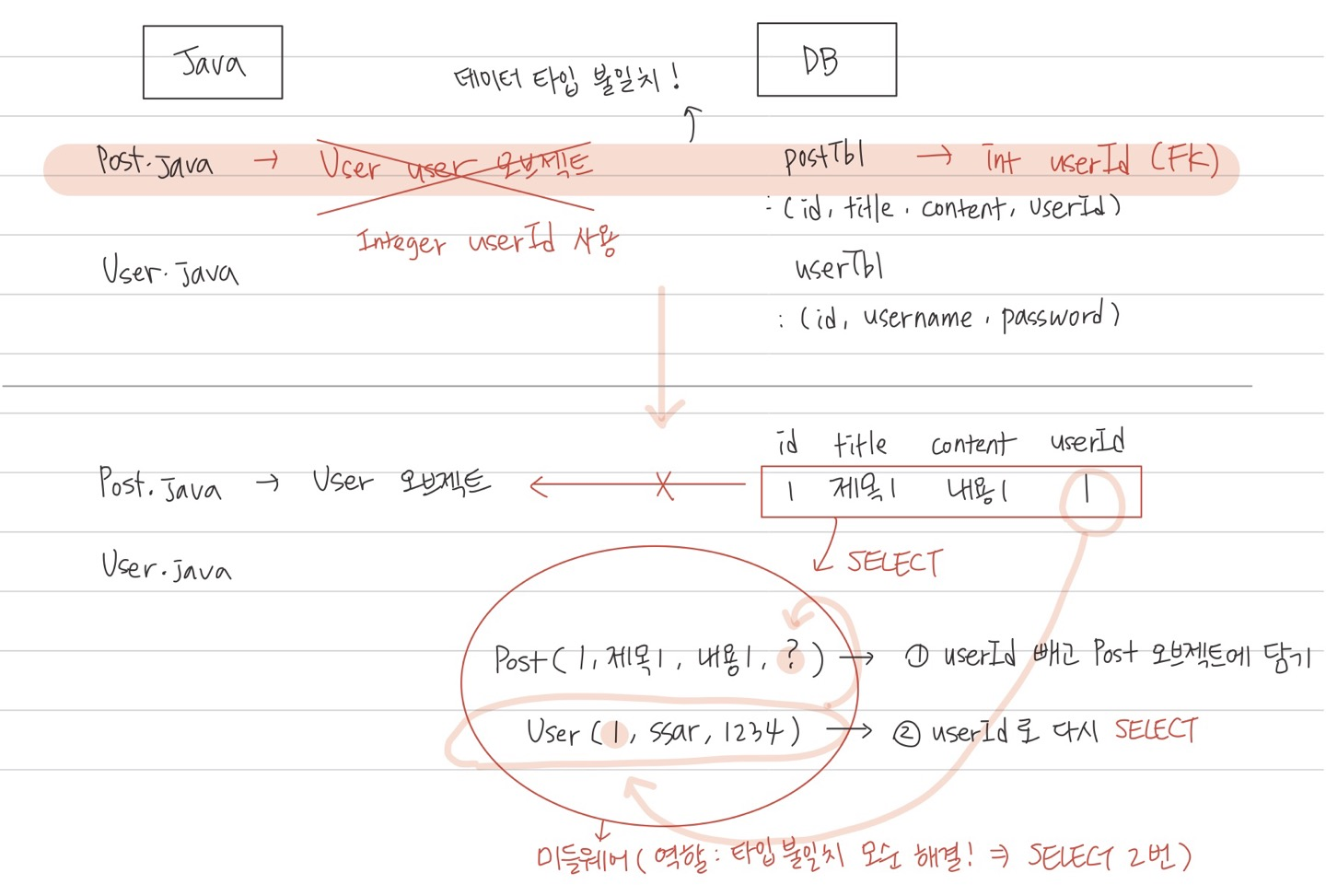
2번의 SELECT과정을 알아서 처리해준다.
엄청 편하다!!!
이때 2번의 SELECT 쿼리를 명령하는 전략 하나와
두 테이블을 JOIN 한 데이터를 한 번에 받아오는 전략,
총 두 가지가 있는데 나중에 선택해서 사용이 가능하다.
이런 전략은 JPA가 제공해준다.

ORM 기술은 hibernate의 기술이다.
Repository와 DB 간의 미들웨어로 작용하고 있는 공간을
영속성 context라고 한다.
영속성 컨텍스트는 자세히 몰라도 됨
다음에 다시 배운다.
따라서 영속성 context는
DB와 Repository의 문맥을
모두 알고 있다.
ORM을 사용하면 모델을 만들 때
자바가 주도권을 쥐고 있는 모델을 만들 수 있다.
그렇게 만들어놓으면 DB에 SELECT 하거나 쿼리를 명령할 때
자동으로 매핑해서 데이터가 쏙쏙 들어간다.
만약 Post 테이블에 다시 SELECT 요청을 하면
영속성 컨텍스트에서 DB까지 다시 가지 않을 것이다.
영속성 컨텍스트가 가져왔던 post 테이블의 정보를 알고 있기 때문에
상대적으로 가까운 거리에서 처리해줄 수 있기 때문이다.
캐싱하는 것이다!
Entity 매핑 어노테이션 정리
https://cjw-awdsd.tistory.com/46
[JPA] 2. 엔티티 매핑 @어노테이션 정리/예제
이번 글에서는 JPA 엔티티 매핑과 관련된 어노테이션 @Entity, @Table, @Id, @Column에 대해 정리한다. 연관관계 매핑 관련 어노테이션은 다음 글에 포스팅하겠다. 1. @Entity @Entity 어노테이션은 JPA를 사용
cjw-awdsd.tistory.com
package site.metacoding.dbproject.domain.post;
import java.time.LocalDateTime;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.Lob;
import javax.persistence.ManyToOne;
import site.metacoding.dbproject.domain.user.User;
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id; // PK
@Column(length = 300, nullable = false) // VARCHAR(300) 길이설정
private String title; // ssar 아이디
// String이면 알아서 CLOB
// Integer면 알아서 BLOB
@Lob // CLOB 4GB 문자 타입
@Column(nullable = false)
private String content;
@JoinColumn(name = "userId") // 컬럼 이름
@ManyToOne // 관계 설정
private User user;
private LocalDateTime createDate;
}

Entity가 테이블의 다른 말이다.
만약 @ManyToOne 어노테이션을 붙여주지 않으면
BeanCreationException이 난다.
Bean은 자바 관점에서
new 되어 heap에 뜬 것들을 Bean이라고 한다.
오브젝트는 아직 메모리에 뜨지 않은 것이다.
메모리에 뜰 가능성이 있는 것을 오브젝트라고 하고,
메모리에 뜬 것은 인스턴스화 되었다고 한다.
인스턴스와 Bean은 같은 말이라고 생각!
EntityManagerFactory는 JPA가 가지고 있는 클래스인데
@Entity가 붙은 클래스와 DB를 연결해준다.
지금은 헷갈리지만 다음에 더 자세히 배우니까
그때 다시 개념을 잡으면 될 것 같다!
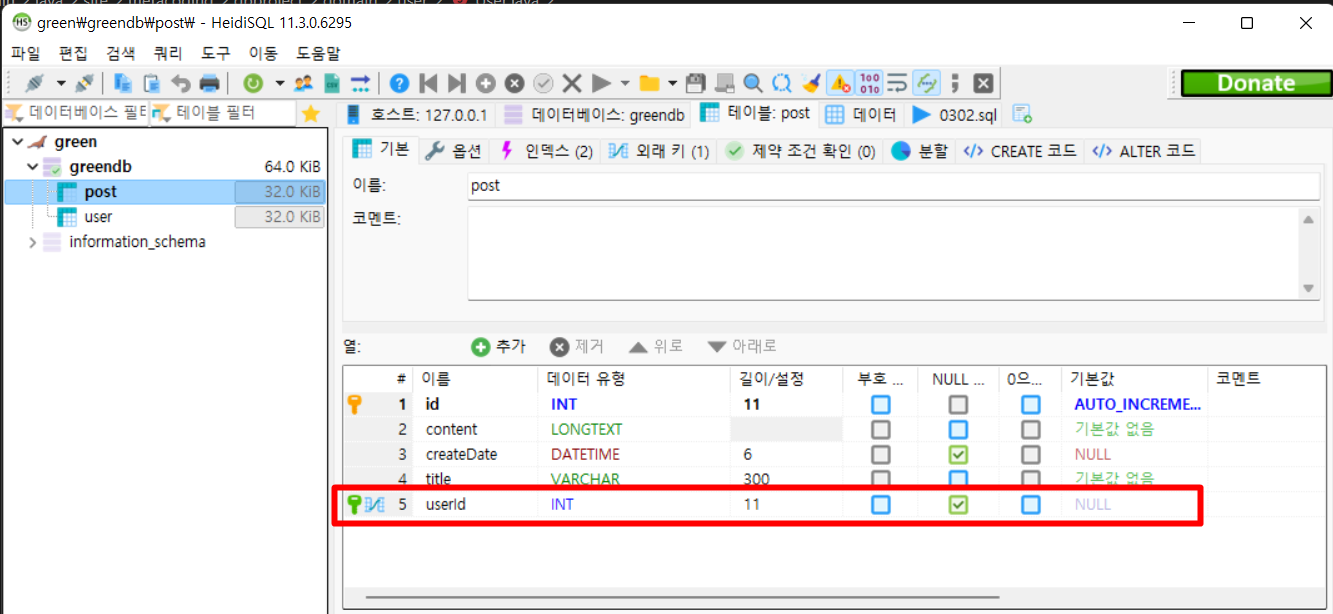
테이블의 연관관계를 생각하여
@ManyToOne 어노테이션을 붙여주고
DB에서 직접 확인을 해보니
userId라고 지정해준 컬럼명으로
외래키 설정까지 되어있는 것을 확인할 수 있다.

[출처]
https://cafe.naver.com/metacoding
메타코딩 : 네이버 카페
코린이들의 궁금증
cafe.naver.com
메타 코딩 유튜브
https://www.youtube.com/c/%EB%A9%94%ED%83%80%EC%BD%94%EB%94%A9
메타코딩
문의사항 : getinthere@naver.com 인스타그램 : https://www.instagram.com/meta4pm 깃헙 : https://github.com/codingspecialist 유료강좌 : https://www.easyupclass.com
www.youtube.com