반응형
데이터프레임을 생성할 때는 dict 타입을 넣어준다.
dict이 키 : 밸류의 모양으로 테이블과 똑같이 생겼으니까!
df = pd.DataFrame({
'A':1,
'B':pd.Timestamp('20220517'),
'C':pd.Series([1, 2, 3, 4]),
'D':'hello'
}) # dict 타입
print(df)
print(df.dtypes)
타입을 확인해보니 문자열은 str 타입이 아닌 오브젝트 타입이다.
데이터프레임의 명령어들을 알아보자.
1. head( )
초반 5개의 데이터를 확인할 수 있다.
df.head()
df에 5개의 데이터가 없기 때문에 4개의 데이터가 출력되었다.
몇개의 데이터가 보고싶은지 파라미터로 지정도 가능하다.
df.head(2)
2. tail( )
head와 반대로 꼬리 데이터도 확인이 가능하다.
df.tail(3)
3. index
데이터프레임의 왼쪽에 자동으로 붙는 인덱스 정보를 볼 수 있다.
df.index
4. columns
컬럼의 타입도 오브젝트임을 확인하고 넘어가자.
df.columns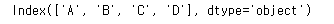
5. values
값만 확인하고 싶을 때 사용한다.
df.values
6. describe( )
전체 데이터의 통계를 보고싶을 때 사용한다.
A, C 컬럼의 통계만 나온다.
즉 숫자 데이터의 통계만 낼 수 있는 것이다.
그렇기 때문에 이전에 남, 여 데이터에 정수화가 필요했던것이다.
df.describe()
7. T
SQL의 피벗과 동일하게 행과 열의 방향을 간단하게 바꿀 수 있다.
df.T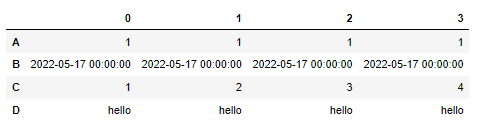
8. sort_index
axis = 0 세로
axis = 1 가로
print(df)
print(df.sort_index(axis=1, ascending=False))
원래 데이터와 비교해보자.
어떤게 달라졌을까?
axis = 1이기 때문에 컬럼이 정렬된것이다.
axis를 0으로 바꾸니 확실히 알 수 있다.
index가 정렬되었다.
print(df.sort_index(axis=0, ascending=False))
sort_index는 값으로 정렬하는게 아니라
컬럼이나 index로 정렬한다.
잘 안쓰이겠다!
9. sort_values( )
얘를 사용하여 값으로 정렬한다.
굉장히 많이쓰인다.
df.sort_values(by='C', ascending=False)
반응형