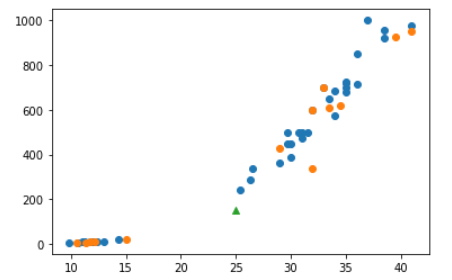
K-최근접 이웃 알고리즘으로 훈련한 데이터에 이상한 점이 발견되었다. 분명 테스트 세트의 도미와 빙어를 모두 올바르게 분류했는데 이 모델에 길이 25cm, 무게 150g 데이터를 넣고 결과를 확인해봤더니 당연히 도미(1)로 예측할 줄 알았으나 빙어(0)로 예측했다. 대체 근처에 있는 이웃이 뭐길래 빙어로 예측했는지 그래프로 확인해보자. import matplotlib.pyplot as plt plt.scatter(train_input[:, 0], train_input[:, 1]) # 모든 행의 length, wieght plt.scatter(test_input[:, 0], test_input[:, 1]) # 모든 행의 length, wieght plt.scatter([25], [150], marker="..