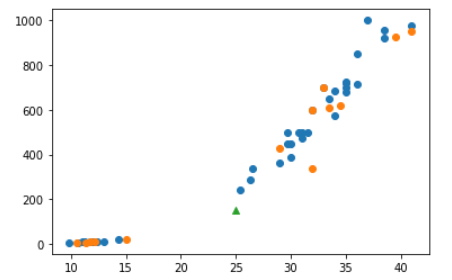
길이라는 특성 하나만으로 무게를 예측한다는 게 말이 안 된다는 지난 시간의 문제점을 해결하기 위해 선형 회귀를 사용해볼 것이다. 선형 회귀에서 선과 점의 오차율은 음수가 될 수도 있기 때문에 모든 손실(잔차) 값에는 제곱을 해준 뒤 더해서 MSE(평균 오차 제곱)를 구한다. 구한 mse가 좋은 건지 알 수 없다. 여러 가지 선을 비교를 해보지 않았기 때문이다. 비교하기 위해 사용하는 게 미분이다. 미분으로 기울기를 변경해가며 mse가 최소인 지점을 찾아야 한다. 이 값이 최소가 되는 회귀식을 찾는 것을 최소 제곱법이라고 하고 방법은 경사 하강법(미분)을 사용해야 한다. 이 선형 회귀 알고리즘이 최소 제곱법을 찾아주고 이때 내부적으로 경사 하강법 알고리즘을 사용하는 것이다. from sklearn.line..